The Default is Cloud — And That's the Problem Der Standard ist Cloud — und genau das ist das Problem
When a manufacturing company evaluates AI solutions, the vendor's architecture slide almost always shows the same thing: your data flows to an external API — OpenAI, Azure, AWS Bedrock — where a large language model processes it and sends back results. The vendor calls it “scalable” and “enterprise-grade.” Wenn ein Fertigungsunternehmen KI-Lösungen evaluiert, zeigt die Architektur-Folie des Anbieters fast immer dasselbe: Ihre Daten fließen an eine externe API — OpenAI, Azure, AWS Bedrock — wo ein Large Language Model sie verarbeitet und Ergebnisse zurücksendet. Der Anbieter nennt es „skalierbar“ und „Enterprise-fähig.“
What they don't emphasize: every prompt you send contains your data. Not metadata. Not anonymized summaries. The actual production numbers, customer names, process parameters, and competitive intelligence that makes your factory run. Was sie nicht betonen: Jeder Prompt enthält Ihre Daten. Keine Metadaten. Keine anonymisierten Zusammenfassungen. Die tatsächlichen Produktionszahlen, Kundennamen, Prozessparameter und das Wettbewerbs-Know-how, das Ihre Fabrik am Laufen hält.
Even with encryption in transit and contractual data processing agreements, you lose something fundamental: control over where your data is processed, how long it's retained, and who has access to the infrastructure. For a factory producing parts for automotive OEMs or aerospace customers, that loss of control is not a theoretical risk — it's a contractual and strategic liability. Selbst mit Verschlüsselung während der Übertragung und vertraglichen Datenverarbeitungsvereinbarungen verlieren Sie etwas Grundlegendes: die Kontrolle darüber, wo Ihre Daten verarbeitet werden, wie lange sie gespeichert werden, und wer Zugang zur Infrastruktur hat. Für eine Fabrik, die Teile für Automobil-OEMs oder Luftfahrtkunden produziert, ist dieser Kontrollverlust kein theoretisches Risiko — es ist eine vertragliche und strategische Haftung.
What Actually Leaves Your Network Was tatsächlich Ihr Netzwerk verlässt
Let's be concrete. An AI agent that analyzes your shopfloor doesn't send a polite question to the cloud. It sends context. Lots of it. Werden wir konkret. Ein KI-Agent, der Ihren Shopfloor analysiert, sendet keine höfliche Frage an die Cloud. Er sendet Kontext. Viel davon.
A Single Prompt to a Cloud LLM Ein einzelner Prompt an ein Cloud-LLM
Prompt excerpt: “Machine SMD-3 produced 1,247 units of article 4711 for BMW with a scrap rate of 4.8%. Cpk on cavity 3 dropped to 1.12 at cycle 812. Tool age: 847 cycles. The order FA-2034 has a delivery deadline of February 16. Current material stock for article 4711: 3,200 units allocated across 4 orders...” Prompt-Auszug: „Maschine SMD-3 hat 1.247 Einheiten von Artikel 4711 für BMW mit einer Ausschussrate von 4,8% produziert. Cpk an Kavität 3 auf 1,12 bei Zyklus 812 gefallen. Werkzeugalter: 847 Zyklen. Auftrag FA-2034 hat Liefertermin 16. Februar. Aktueller Materialbestand für Artikel 4711: 3.200 Einheiten auf 4 Aufträge verteilt...“
That single prompt contains: customer name, article number, production volume, quality metrics, tool wear data, order deadlines, and inventory levels. Now multiply this by 50 agent calls per analysis, 6 analyses per day. That's 300 API calls daily, each containing sensitive production data. Dieser einzelne Prompt enthält: Kundenname, Artikelnummer, Produktionsvolumen, Qualitätskennzahlen, Werkzeugverschleißdaten, Liefertermine und Lagerstände. Multiplizieren Sie das mit 50 Agenten-Calls pro Analyse, 6 Analysen pro Tag. Das sind 300 API-Calls täglich, jeder mit sensiblen Produktionsdaten.
All of this data is now on Microsoft's, OpenAI's, or Amazon's servers. Even if they promise not to train on it — it was processed there, logged there, and stored there, at least temporarily. All diese Daten befinden sich jetzt auf den Servern von Microsoft, OpenAI oder Amazon. Selbst wenn sie versprechen, nicht damit zu trainieren — sie wurden dort verarbeitet, protokolliert und gespeichert, zumindest temporär.
Compliance Is Not Just a Checkbox Compliance ist keine Checkbox
The legal exposure goes beyond good intentions. Three categories of data make cloud-based AI processing problematic for manufacturing: Die rechtliche Exposition geht über gute Absichten hinaus. Drei Datenkategorien machen cloudbasierte KI-Verarbeitung für die Fertigung problematisch:
GDPR — Personal data in production context. Customer names appear in order data. Employee names appear in shift schedules and quality sign-offs. Sending these to a US-based API creates a data transfer outside the EU that requires specific legal basis under GDPR Articles 44–49. Standard Contractual Clauses exist, but they add complexity and audit obligations that most AI vendors gloss over. DSGVO — Personenbezogene Daten im Produktionskontext. Kundennamen erscheinen in Auftragsdaten. Mitarbeiternamen in Schichtplänen und Qualitätsfreigaben. Diese an eine US-basierte API zu senden erzeugt einen Datentransfer außerhalb der EU, der eine spezifische Rechtsgrundlage nach DSGVO Artikel 44–49 erfordert. Standardvertragsklauseln existieren, aber sie erhöhen die Komplexität und Prüfpflichten, über die die meisten KI-Anbieter hinweggehen.
Trade secrets — Process parameters and cycle times. Your specific injection molding parameters, cavity balance settings, tool change intervals, and machine configurations represent years of process optimization. These are trade secrets. Once they leave your network in an API call, you cannot prove they weren't accessed, copied, or inadvertently leaked. Geschäftsgeheimnisse — Prozessparameter und Taktzeiten. Ihre spezifischen Spritzgießparameter, Kavitätenbalance-Einstellungen, Werkzeugwechselintervalle und Maschinenkonfigurationen repräsentieren Jahre der Prozessoptimierung. Das sind Geschäftsgeheimnisse. Sobald sie Ihr Netzwerk in einem API-Call verlassen, können Sie nicht beweisen, dass sie nicht eingesehen, kopiert oder unbeabsichtigt weitergegeben wurden.
NDA obligations — Customer-specific articles. If you produce parts for an automotive OEM under NDA, that NDA typically covers production volumes, delivery schedules, and quality specifications. An AI prompt that contains “1,247 units of article 4711 for BMW” may already violate the NDA if processed on third-party infrastructure. NDA-Pflichten — Kundenspezifische Artikel. Wenn Sie Teile für einen Automobil-OEM unter NDA produzieren, deckt diese NDA typischerweise Produktionsvolumen, Lieferpläne und Qualitätsspezifikationen ab. Ein KI-Prompt mit „1.247 Einheiten von Artikel 4711 für BMW“ kann bereits das NDA verletzen, wenn er auf Drittanbieter-Infrastruktur verarbeitet wird.
The real risk: One data breach at an AI provider doesn't just expose your data — it exposes your customers' data. A single incident could trigger NDA violations, GDPR fines, and loss of customer trust simultaneously. The cost of that scenario dwarfs any savings from using cheaper cloud APIs. Das eigentliche Risiko: Ein Datenleck bei einem KI-Anbieter exponiert nicht nur Ihre Daten — es exponiert die Daten Ihrer Kunden. Ein einzelner Vorfall kann NDA-Verletzungen, DSGVO-Bußgelder und Vertrauensverlust gleichzeitig auslösen. Die Kosten dieses Szenarios übersteigen jede Ersparnis durch billigere Cloud-APIs bei weitem.
The Hardware Reality Die Hardware-Realität
The most common objection to on-premise AI is cost. “We can't afford our own GPU infrastructure.” This was true in 2023. It is no longer true in 2026. Der häufigste Einwand gegen On-Premise-KI sind die Kosten. „Wir können uns keine eigene GPU-Infrastruktur leisten.“ Das stimmte 2023. Es stimmt 2026 nicht mehr.
Modern quantized models — specifically Qwen 2.5 72B at Q4_K_M quantization — run effectively on consumer-grade GPUs. You don't need an NVIDIA H100 cluster. You need a server with multiple RTX cards and enough VRAM to hold the model in memory. Moderne quantisierte Modelle — speziell Qwen 2.5 72B bei Q4_K_M-Quantisierung — laufen effektiv auf Consumer-GPUs. Sie brauchen keinen NVIDIA-H100-Cluster. Sie brauchen einen Server mit mehreren RTX-Karten und genug VRAM, um das Modell im Speicher zu halten.
Cost comparison: Kostenvergleich:
On-premise (one-time): 5x NVIDIA RTX 3060 (12 GB VRAM each) = ~€6,000. Server hardware, PSU, motherboard = ~€2,000. Total: ~€8,000 one-time investment. On-Premise (einmalig): 5x NVIDIA RTX 3060 (12 GB VRAM je) = ~€6.000. Server-Hardware, Netzteil, Mainboard = ~€2.000. Gesamt: ~€8.000 einmalige Investition.
Cloud (monthly): GPT-4-class API for equivalent workload (300 calls/day, ~4,000 tokens each) = €3,000–8,000/month. Cloud (monatlich): GPT-4-Klasse API für äquivalente Last (300 Calls/Tag, ~4.000 Tokens je) = €3.000–8.000/Monat.
Break-even: under 2 months. After that, on-premise inference is essentially free (electricity costs: ~€80–120/month under load). Break-even: unter 2 Monaten. Danach ist On-Premise-Inferenz im Wesentlichen kostenlos (Stromkosten: ~€80–120/Monat unter Last).
Latency: On-premise = 50–200 ms per token. Cloud API = 500 ms–2 s per response (plus network roundtrip). On-premise is 3–10x faster for interactive use. Latenz: On-Premise = 50–200 ms pro Token. Cloud-API = 500 ms–2 s pro Antwort (plus Netzwerk-Roundtrip). On-Premise ist 3–10x schneller für interaktive Nutzung.
What We Run Was wir betreiben
This is not theoretical. Our production system runs entirely on-premise. Here is the concrete setup: Das ist nicht theoretisch. Unser Produktionssystem läuft vollständig on-premise. Hier ist das konkrete Setup:
- 5x NVIDIA RTX 3060 (12 GB VRAM each) — GPU inference server 5x NVIDIA RTX 3060 (12 GB VRAM je) — GPU-Inferenz-Server
- llama.cpp server — optimized C++ inference engine llama.cpp Server — optimierte C++ Inferenz-Engine
- Qwen 2.5 72B (Q4_K_M quantization) — 72 billion parameters, running locally Qwen 2.5 72B (Q4_K_M-Quantisierung) — 72 Milliarden Parameter, lokal betrieben
- MicroK8s cluster — container orchestration for MCP servers and agents MicroK8s-Cluster — Container-Orchestrierung für MCP-Server und Agenten
- PostgreSQL + TimescaleDB — production data, time-series, quality metrics PostgreSQL + TimescaleDB — Produktionsdaten, Zeitreihen, Qualitätskennzahlen
- Redis — job queues, caching, real-time state Redis — Job-Queues, Caching, Echtzeit-Status
Zero cloud dependencies. No data leaves the network. The entire stack can run air-gapped if required. Every database query, every LLM inference, every agent decision happens on hardware that the factory controls. Null Cloud-Abhängigkeiten. Keine Daten verlassen das Netzwerk. Der gesamte Stack kann bei Bedarf air-gapped betrieben werden. Jede Datenbankabfrage, jede LLM-Inferenz, jede Agenten-Entscheidung passiert auf Hardware, die die Fabrik kontrolliert.
For a deeper look at the multi-agent architecture that runs on this infrastructure, see our technology page and the companion article on why dashboards fail. Für einen tieferen Einblick in die Multi-Agenten-Architektur, die auf dieser Infrastruktur läuft, siehe unsere Technologie-Seite und den Begleitartikel über warum Dashboards scheitern.
“But Cloud Scales Better” „Aber die Cloud skaliert besser“
This is the most common counterargument, and it deserves a direct answer. Das ist das häufigste Gegenargument, und es verdient eine direkte Antwort.
Yes, cloud scales better — for workloads that need to scale. A social media company processing millions of user queries per second needs elastic cloud infrastructure. A factory with 20–50 machines running 6 analyses per day does not. Ja, die Cloud skaliert besser — für Workloads, die skalieren müssen. Ein Social-Media-Unternehmen, das Millionen Nutzeranfragen pro Sekunde verarbeitet, braucht elastische Cloud-Infrastruktur. Eine Fabrik mit 20–50 Maschinen und 6 Analysen pro Tag nicht.
The manufacturing AI workload is fundamentally different from consumer AI. You're not building a chatbot that serves 100,000 concurrent users. You're running structured analytical tasks on a fixed set of machines, orders, and processes. The data volume is predictable. The query pattern is regular. The peak load is known in advance (morning report at 06:00, optimization runs at shift changes). Der KI-Workload in der Fertigung unterscheidet sich grundlegend von Consumer-KI. Sie bauen keinen Chatbot für 100.000 gleichzeitige Nutzer. Sie führen strukturierte Analyseaufgaben auf einem festen Satz von Maschinen, Aufträgen und Prozessen aus. Das Datenvolumen ist vorhersehbar. Das Abfragemuster regelmäßig. Die Spitzenlast vorab bekannt (Morgenbericht um 06:00, Optimierungsläufe bei Schichtwechsel).
72 billion parameters is more than enough for structured manufacturing analysis. You're not writing novels or generating creative content. You're analyzing KPIs, identifying root causes, and recommending concrete actions. A well-tuned 72B model outperforms GPT-4 on domain-specific manufacturing tasks when given the right context — because it's dedicated to your workload, not shared across millions of users. 72 Milliarden Parameter reichen für strukturierte Fertigungsanalysen mehr als aus. Sie schreiben keine Romane und generieren keine kreativen Inhalte. Sie analysieren KPIs, identifizieren Ursachen und empfehlen konkrete Maßnahmen. Ein gut abgestimmtes 72B-Modell übertrifft GPT-4 bei domänenspezifischen Fertigungsaufgaben, wenn es den richtigen Kontext bekommt — weil es Ihrem Workload gewidmet ist, nicht über Millionen Nutzer geteilt.
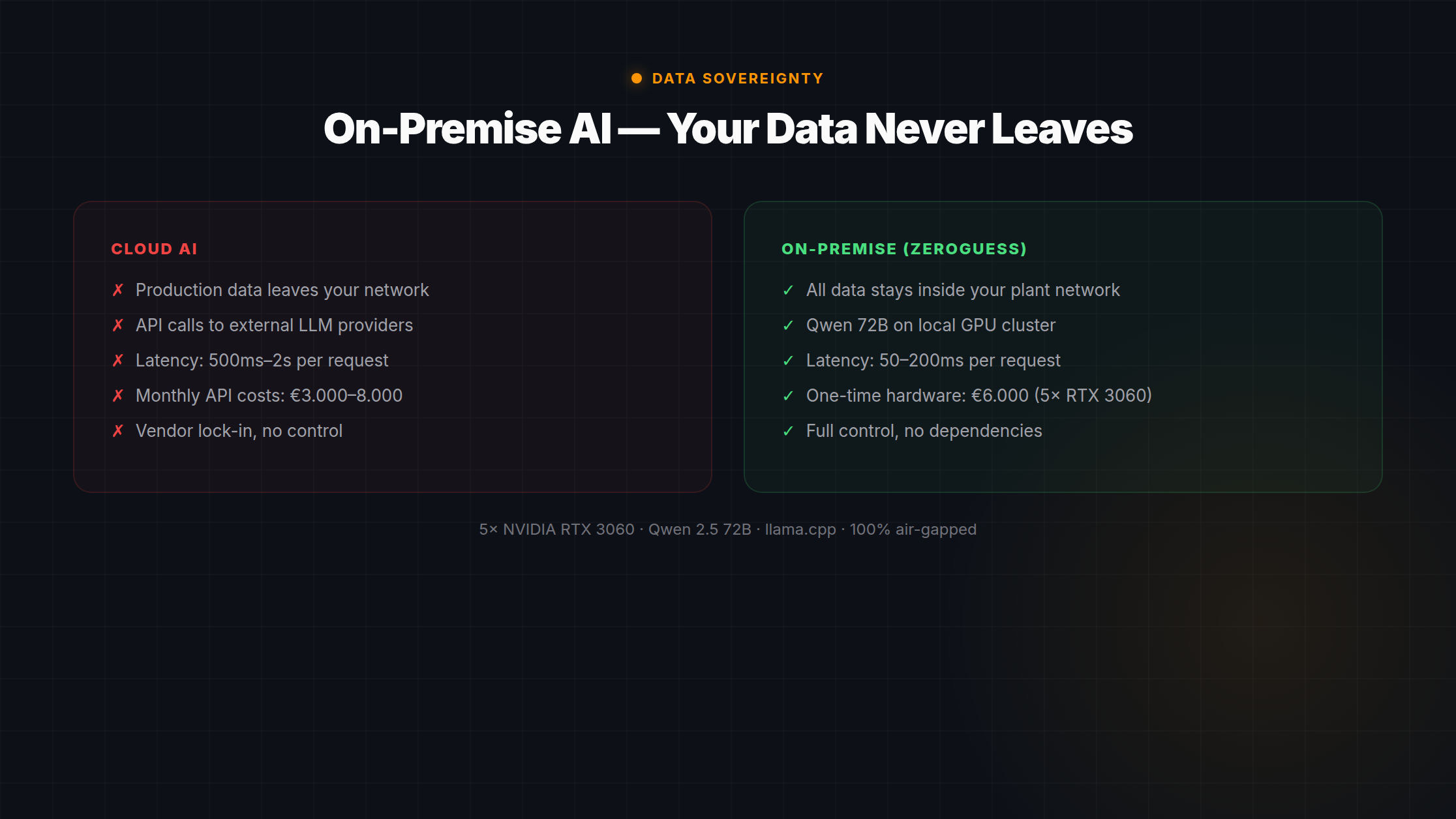
Cloud AI Cloud-KI
- Production data leaves your networkProduktionsdaten verlassen Ihr Netzwerk
- 500 ms–2 s latency per response500 ms–2 s Latenz pro Antwort
- €3,000–8,000/month recurring cost€3.000–8.000/Monat laufende Kosten
- Vendor can change pricing, models, or termsAnbieter kann Preise, Modelle oder Bedingungen ändern
- Requires internet connectivityErfordert Internetverbindung
- GDPR complexity for EU manufacturersDSGVO-Komplexität für EU-Hersteller
On-Premise AI On-Premise-KI
- Data never leaves your plant networkDaten verlassen nie Ihr Werksnetzwerk
- 50–200 ms latency per token50–200 ms Latenz pro Token
- ~€8,000 one-time, ~€100/month electricity~€8.000 einmalig, ~€100/Monat Strom
- You own the hardware and model weightsSie besitzen Hardware und Modellgewichte
- Works fully air-gapped if neededFunktioniert bei Bedarf vollständig air-gapped
- Full GDPR compliance by defaultVolle DSGVO-Konformität standardmäßig
The cloud scaling argument solves a problem that manufacturing AI doesn't have. What manufacturing does have is a data sovereignty problem, a latency problem, and a cost problem — and on-premise solves all three. Das Cloud-Skalierungsargument löst ein Problem, das Fertigungs-KI nicht hat. Was die Fertigung hat, ist ein Datensouveränitäts-Problem, ein Latenz-Problem und ein Kosten-Problem — und On-Premise löst alle drei.
Bottom line: On-premise AI is not a compromise. For manufacturing, it is the technically superior, legally safer, and economically cheaper option. The only reason cloud is still the default is that most AI vendors don't offer an on-premise alternative — because their business model depends on recurring API fees. Fazit: On-Premise-KI ist kein Kompromiss. Für die Fertigung ist es die technisch überlegene, rechtlich sicherere und wirtschaftlich günstigere Option. Der einzige Grund, warum Cloud noch der Standard ist: Die meisten KI-Anbieter bieten keine On-Premise-Alternative — weil ihr Geschäftsmodell auf wiederkehrenden API-Gebühren basiert.