Why Single-Pass Analysis Fails Warum Ein-Durchlauf-Analysen scheitern
The obvious approach to AI-driven manufacturing analysis is straightforward: collect all the data, dump it into a prompt, and ask a large language model to analyze it. One call, one response, done. This is how most teams start. And it works — until it doesn't. Der naheliegende Ansatz für KI-gestützte Fertigungsanalyse ist direkt: Alle Daten sammeln, in einen Prompt packen und ein Large Language Model bitten, sie zu analysieren. Ein Aufruf, eine Antwort, fertig. So fangen die meisten Teams an. Und es funktioniert — bis es das nicht mehr tut.
The problem is structural. A single LLM call with 50,000 tokens of factory data will produce a plausible-sounding summary. It will identify some patterns. But it cannot know what questions to ask. It sees only the data you gave it. If the root cause requires cross-referencing OEE data with tool change history and SPC trends, but you only included the OEE data — the model will confidently analyze what it has and miss what it doesn't. Das Problem ist strukturell. Ein einzelner LLM-Aufruf mit 50.000 Token Fabrikdaten wird eine plausibel klingende Zusammenfassung produzieren. Er wird einige Muster erkennen. Aber er kann nicht wissen, welche Fragen zu stellen sind. Er sieht nur die Daten, die Sie ihm gegeben haben. Wenn die Ursache einen Abgleich von OEE-Daten mit Werkzeugwechselhistorie und SPC-Trends erfordert, Sie aber nur die OEE-Daten mitgegeben haben — wird das Modell selbstsicher analysieren, was es hat, und verpassen, was fehlt.
Worse: it has no internal cross-checking mechanism. If the model claims “tool wear caused the OEE drop,” there is no second opinion. No maintenance specialist pushes back with “actually, that was a scheduled calibration.” No quality engineer checks whether the Cpk data supports or contradicts the hypothesis. The model generates one narrative and commits to it. Schlimmer noch: Es hat keinen internen Gegenprüfungs-Mechanismus. Wenn das Modell behauptet „Werkzeugverschleiß verursachte den OEE-Einbruch“, gibt es keine zweite Meinung. Kein Wartungsspezialist widerspricht mit „tatsächlich war das eine geplante Kalibrierung“. Kein Qualitätsingenieur prüft, ob die Cpk-Daten die Hypothese stützen oder widerlegen. Das Modell generiert eine Erzählung und bleibt dabei.
Manufacturing decisions need what experienced teams provide: domain-specific analysis, cross-domain verification, and structured debate before acting. That is exactly what the 3-round debate protocol replicates in software. Fertigungsentscheidungen brauchen, was erfahrene Teams liefern: domänenspezifische Analyse, domänenübergreifende Verifikation und strukturierte Debatte vor dem Handeln. Genau das bildet das 3-Runden-Debattenprotokoll in Software ab.
Architectural insight: The debate protocol is not about getting a “better answer” from a model. It is about building a system where wrong answers get caught. The value comes from contradiction detection, not from generation quality. Architektur-Erkenntnis: Das Debattenprotokoll zielt nicht auf eine „bessere Antwort“ vom Modell. Es geht darum, ein System zu bauen, in dem falsche Antworten auffallen. Der Wert kommt aus der Widerspruchserkennung, nicht aus der Generierungsqualität.
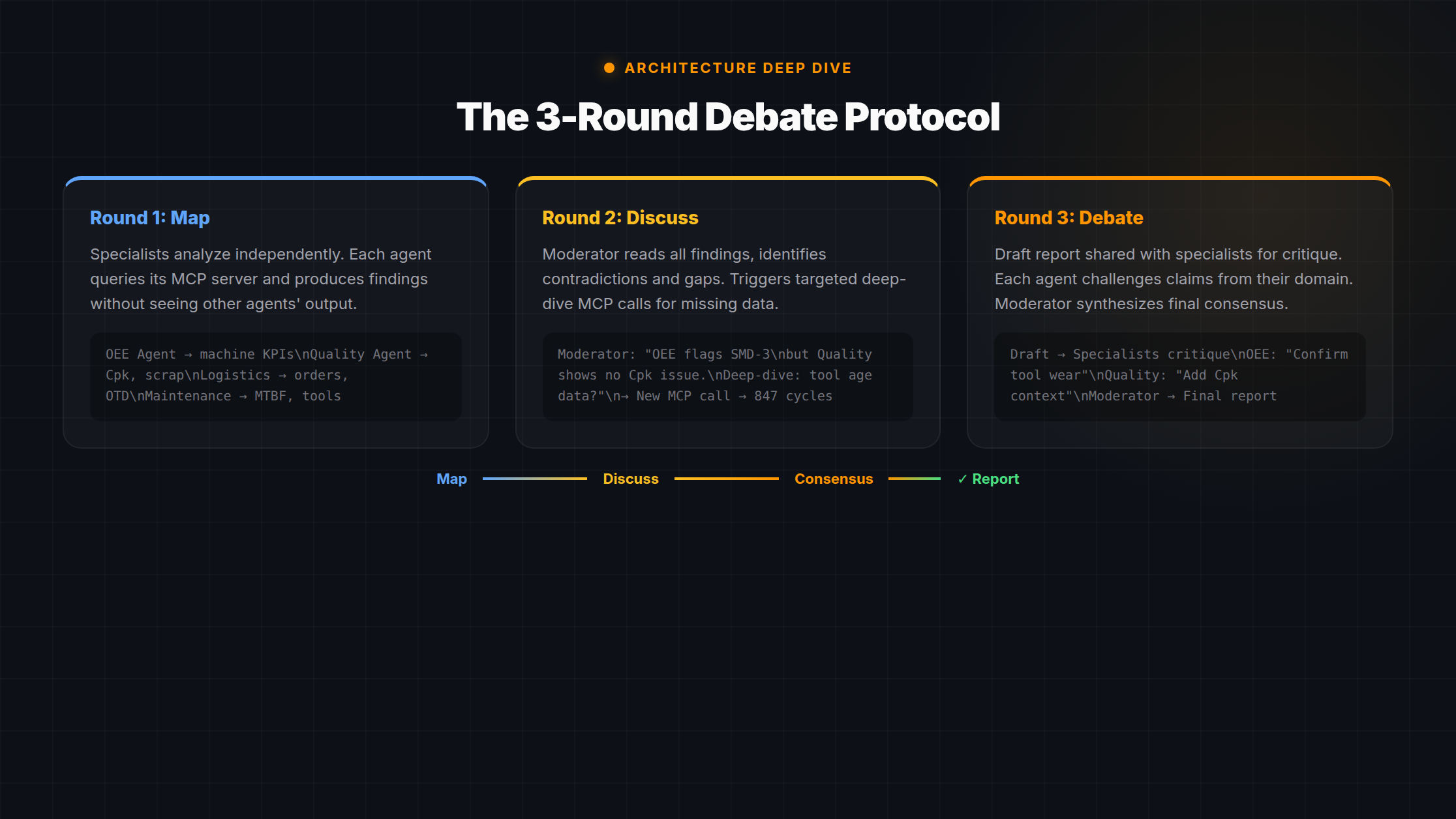
Round 1: Map (Parallel Specialist Analysis) Runde 1: Map (Parallele Spezialistenanalyse)
The first round follows the “map” pattern from map-reduce. Five to six specialist agents each receive domain-specific data from MCP servers and analyze independently. The critical design decision: specialists do not see each other's output. This prevents groupthink. Each agent forms its own assessment based solely on its domain data. Die erste Runde folgt dem „Map“-Muster aus Map-Reduce. Fünf bis sechs Spezialagenten erhalten jeweils domänenspezifische Daten von MCP-Servern und analysieren unabhängig. Die entscheidende Design-Entscheidung: Spezialisten sehen nicht die Ergebnisse der anderen. Das verhindert Gruppendenken. Jeder Agent bildet seine eigene Einschätzung ausschließlich auf Basis seiner Domänendaten.
Each specialist has its own externalized prompt file (config/prompts/agents/*.md) with domain-specific instructions. These prompts use {{variable}} template syntax and are hot-reloaded during development — you can change a prompt, save the file, and the next agent run picks up the new version without restart.
Jeder Spezialist hat seine eigene externalisierte Prompt-Datei (config/prompts/agents/*.md) mit domänenspezifischen Instruktionen. Diese Prompts verwenden {{variable}}-Template-Syntax und werden im Development-Modus hot-reloaded — man kann einen Prompt ändern, die Datei speichern, und der nächste Agent-Durchlauf nutzt die neue Version ohne Neustart.
Here is what each specialist receives and analyzes: Das erhält und analysiert jeder Spezialist:
OEE Specialist OEE-Spezialist
- Hourly OEE data per machineStündliche OEE-Daten je Maschine
- Downtime events and durationsStillstandsereignisse und Dauern
- Tool change historiesWerkzeugwechsel-Historien
- Availability, performance, quality splitsVerfügbarkeit, Leistung, Qualität aufgeteilt
Quality Specialist Qualitäts-Spezialist
- Cpk values per cavity/processCpk-Werte je Kavität/Prozess
- Scrap rates and trendsAusschussraten und Trends
- SPC control chart dataSPC-Regelkarten-Daten
- Open quality notificationsOffene Qualitätsmeldungen
Additional specialists cover production planning (order status, capacity, shift schedules), maintenance (MTBF, open work orders, spare parts), and logistics (material availability, delivery schedules, warehouse levels). The production specialist typically handles the most data — around 7,000 characters of context — and needs roughly 10 minutes of LLM processing time on a Qwen 72B model. Weitere Spezialisten decken Produktionsplanung (Auftragsstatus, Kapazität, Schichtpläne), Instandhaltung (MTBF, offene Arbeitsaufträge, Ersatzteile) und Logistik (Materialverfügbarkeit, Liefertermine, Lagerbestände) ab. Der Produktionsspezialist verarbeitet typischerweise die meisten Daten — etwa 7.000 Zeichen Kontext — und benötigt rund 10 Minuten LLM-Verarbeitungszeit auf einem Qwen 72B Modell.
Because all specialists run in parallel, the total time for Round 1 is determined by the slowest specialist — not the sum of all specialists. Five agents that each take 10 minutes still finish in 10 minutes, not 50. Da alle Spezialisten parallel laufen, wird die Gesamtzeit für Runde 1 durch den langsamsten Spezialisten bestimmt — nicht die Summe aller. Fünf Agenten, die jeweils 10 Minuten brauchen, sind trotzdem in 10 Minuten fertig, nicht in 50.
Why isolation matters: If the OEE specialist knows what the quality specialist found, it will anchor on those findings. It might skip its own analysis of downtime patterns because the quality data already “explains” the issue. Independent analysis forces each specialist to extract maximum signal from its own data domain. Contradictions between independent findings are the most valuable output of Round 1. Warum Isolation wichtig ist: Wenn der OEE-Spezialist weiß, was der Qualitätsspezialist gefunden hat, wird er sich an diesen Ergebnissen orientieren. Er könnte seine eigene Analyse der Stillstandsmuster überspringen, weil die Qualitätsdaten das Problem bereits „erklären“. Unabhängige Analyse zwingt jeden Spezialisten, maximales Signal aus seiner eigenen Datendumäne zu extrahieren. Widersprüche zwischen unabhängigen Erkenntnissen sind das wertvollste Ergebnis von Runde 1.
Round 2: Discussion (Moderator-Driven Deep Dive) Runde 2: Diskussion (Moderator-gesteuerter Deep Dive)
The moderator agent reads ALL specialist findings from Round 1. Its job is not to summarize — it is to find contradictions, gaps, and cross-domain connections. This is where the protocol diverges fundamentally from simple aggregation. Der Moderator-Agent liest ALLE Spezialistenergebnisse aus Runde 1. Seine Aufgabe ist nicht, zusammenzufassen — sondern Widersprüche, Lücken und domänenübergreifende Zusammenhänge zu finden. Hier weicht das Protokoll fundamental von einfacher Aggregation ab.
The moderator generates targeted questions. These questions are not rhetorical — they trigger new MCP calls. Data that was not part of the original query gets fetched on demand, based on the gaps the moderator identified. This is the “smart deep-dive”: the system decides what additional data to fetch based on what it found so far. Der Moderator generiert gezielte Fragen. Diese Fragen sind nicht rhetorisch — sie lösen neue MCP-Aufrufe aus. Daten, die nicht Teil der ursprünglichen Abfrage waren, werden bedarfsgesteuert geholt, basierend auf den Lücken, die der Moderator identifiziert hat. Das ist der „Smart Deep-Dive“: Das System entscheidet, welche zusätzlichen Daten es holen soll, basierend auf dem, was es bisher gefunden hat.
The Case of the Missing 47 Minutes Der Fall der fehlenden 47 Minuten
Round 1 produces two contradictory findings. Watch how the moderator resolves it: Runde 1 produziert zwei widersprüchliche Ergebnisse. So löst der Moderator den Widerspruch auf:
- OEE Specialist → "47-min unplanned stoppage on Line 3 at 02:14. OEE impact: -12pp." OEE-Spezialist → "47 Min. ungeplanter Stillstand an Linie 3 um 02:14. OEE-Auswirkung: -12pp."
- Maintenance Specialist → "No unplanned maintenance events on Line 3 in the last 24h." Wartungs-Spezialist → "Keine ungeplanten Wartungsereignisse an Linie 3 in den letzten 24h."
- Moderator → CONTRADICTION DETECTED. "OEE shows 47-min stop, maintenance shows nothing. Questions: (1) What was the tool age on Line 3? (2) Was there a calibration event? (3) Check shift handover notes." Moderator → WIDERSPRUCH ERKANNT. "OEE zeigt 47-Min-Stopp, Wartung zeigt nichts. Fragen: (1) Wie alt war das Werkzeug an Linie 3? (2) Gab es ein Kalibrierereignis? (3) Schichtübergabe-Notizen prüfen."
- NEW MCP CALLS: wzm_get_tool_changes(Line 3) → tool age 847 cycles. get_calibration_log(Line 3) → scheduled calibration at 02:10, duration ~45 min. NEUE MCP-AUFRUFE: wzm_get_tool_changes(Linie 3) → Werkzeugalter 847 Zyklen. get_calibration_log(Linie 3) → geplante Kalibrierung um 02:10, Dauer ~45 Min.
- Moderator → RESOLVED: "The 47-min stop was a scheduled calibration, not an unplanned failure. OEE classification should be 'planned downtime,' not 'unplanned.' Root cause is not equipment failure." Moderator → GELÖST: "Der 47-Min-Stopp war eine geplante Kalibrierung, kein ungeplanter Ausfall. OEE-Klassifizierung sollte 'geplanter Stillstand' sein, nicht 'ungeplant.' Ursache ist kein Geräteausfall."
Without Round 2, the final report would have flagged Line 3 as having an equipment reliability problem. The actual situation: a routine calibration that was correctly scheduled but miscategorized in the MES. The moderator’s targeted questions — and the new data they fetched — changed the conclusion entirely. Ohne Runde 2 hätte der Abschlussbericht Linie 3 als Geräte-Zuverlässigkeitsproblem markiert. Die tatsächliche Situation: eine routinemäßige Kalibrierung, die korrekt geplant, aber im MES falsch klassifiziert war. Die gezielten Fragen des Moderators — und die neu abgerufenen Daten — änderten die Schlussfolgerung komplett.
A key implementation detail: the moderator receives previousDiscussionContext from any earlier iterations. This prevents it from re-asking questions that were already answered. Each iteration of Round 2 builds on the last, producing richer analysis with each pass.
Ein wichtiges Implementierungsdetail: Der Moderator erhält previousDiscussionContext aus früheren Iterationen. Das verhindert, dass er bereits beantwortete Fragen erneut stellt. Jede Iteration von Runde 2 baut auf der vorherigen auf und produziert mit jedem Durchlauf reichhaltigere Analyse.
Round 3: Debate + Synthesis Runde 3: Debatte + Synthese
The moderator creates a draft report based on all findings from Rounds 1 and 2. But the draft is not the final output. It goes back to each specialist for critique. Der Moderator erstellt einen Berichtsentwurf basierend auf allen Erkenntnissen aus Runden 1 und 2. Aber der Entwurf ist nicht die finale Ausgabe. Er geht zurück an jeden Spezialisten zur Kritik.
Each specialist receives the draft and evaluates it from their domain perspective only. They are not asked “is this report good?” — they are asked “does this report accurately represent what your data shows?” This is a fundamentally different question. It forces each specialist to check whether their findings were correctly incorporated, whether any nuance was lost, and whether the proposed actions make sense given the data they analyzed. Jeder Spezialist erhält den Entwurf und bewertet ihn ausschließlich aus seiner Domänenperspektive. Es wird nicht gefragt „Ist dieser Bericht gut?“ — sondern „Gibt dieser Bericht korrekt wieder, was Ihre Daten zeigen?“ Das ist eine fundamental andere Frage. Sie zwingt jeden Spezialisten zu prüfen, ob seine Erkenntnisse korrekt eingeflossen sind, ob Nuancen verloren gingen und ob die vorgeschlagenen Maßnahmen angesichts der analysierten Daten sinnvoll sind.
Specialist Critique Corrects the Draft Spezialisten-Kritik korrigiert den Entwurf
- Moderator Draft → "Line 3 OEE drop was caused by tool wear at 847 cycles, exceeding the 800-cycle recommended interval..." Moderator-Entwurf → "OEE-Einbruch an Linie 3 wurde durch Werkzeugverschleiß bei 847 Zyklen verursacht, über dem empfohlenen 800-Zyklen-Intervall..."
- OEE Specialist → CRITIQUE: "The draft claims tool wear caused the OEE drop. My data shows the 47-min stoppage occurred during a planned calibration window — not a tool failure. The OEE impact is real, but the root cause attribution is wrong." OEE-Spezialist → KRITIK: "Der Entwurf behauptet Werkzeugverschleiß verursachte den OEE-Einbruch. Meine Daten zeigen, dass der 47-Min-Stillstand während eines geplanten Kalibrierfensters stattfand — kein Werkzeugausfall. Die OEE-Auswirkung ist real, aber die Ursachenzuordnung ist falsch."
- Maintenance Specialist → CONFIRMS: "Scheduled calibration on Line 3, approximately 45 minutes. This is a recurring monthly event. Tool age at 847 cycles is within acceptable range for this tool type." Wartungs-Spezialist → BESTÄTIGT: "Geplante Kalibrierung an Linie 3, ca. 45 Minuten. Dies ist ein monatlich wiederkehrendes Ereignis. Werkzeugalter von 847 Zyklen ist im akzeptablen Bereich für diesen Werkzeugtyp."
- Quality Specialist → ADDS: "Post-calibration Cpk values returned to 1.67 within 20 minutes. No quality impact from the stoppage. The calibration was effective." Qualitäts-Spezialist → ERGÄNZT: "Cpk-Werte nach Kalibrierung kehrten innerhalb von 20 Minuten auf 1,67 zurück. Keine Qualitätsauswirkung durch den Stillstand. Die Kalibrierung war wirksam."
- Moderator Final → REVISED: "Line 3 stoppage was planned maintenance (calibration), not tool failure. OEE dip is expected and recurring. Recommendation: reclassify in MES as planned downtime. No corrective action needed." Moderator Final → REVIDIERT: "Stillstand an Linie 3 war geplante Wartung (Kalibrierung), kein Werkzeugausfall. OEE-Einbruch ist erwartet und wiederkehrend. Empfehlung: Im MES als geplanten Stillstand umklassifizieren. Keine Korrekturmaßnahme nötig."
The final report now reflects verified consensus — not the moderator's initial interpretation, but an interpretation that survived critique from every domain. Without the debate round, the team might have initiated an unnecessary tool change and investigated a non-existent reliability problem. Der Abschlussbericht spiegelt nun verifizierten Konsens wider — nicht die anfängliche Interpretation des Moderators, sondern eine Interpretation, die die Kritik jeder Domäne überstanden hat. Ohne die Debattenrunde hätte das Team möglicherweise einen unnötigen Werkzeugwechsel eingeleitet und ein nicht existierendes Zuverlässigkeitsproblem untersucht.
The result is consensus — not majority vote. The moderator does not count how many specialists agree. It synthesizes a conclusion that addresses every critique. If a specialist's objection cannot be resolved, it is flagged as an open question in the final report, not silently dropped. Das Ergebnis ist Konsens — keine Mehrheitsabstimmung. Der Moderator zählt nicht, wie viele Spezialisten zustimmen. Er synthetisiert eine Schlussfolgerung, die jede Kritik adressiert. Wenn der Einwand eines Spezialisten nicht aufgelöst werden kann, wird er als offene Frage im Abschlussbericht markiert, nicht stillschweigend gestrichen.
Implementation Details Implementierungsdetails
The protocol is orchestrated by a LangGraph state machine. Each phase (map, discussion, debate) is a node in the graph. Transitions are deterministic: Round 1 always completes before Round 2 starts. The state object carries specialist findings, moderator questions, fetched data, and critique results through the entire flow. Das Protokoll wird von einer LangGraph State Machine orchestriert. Jede Phase (Map, Diskussion, Debatte) ist ein Knoten im Graphen. Übergänge sind deterministisch: Runde 1 wird immer abgeschlossen, bevor Runde 2 beginnt. Das State-Objekt trägt Spezialistenergebnisse, Moderator-Fragen, abgerufene Daten und Kritik-Ergebnisse durch den gesamten Ablauf.
Key technical parameters: Wichtige technische Parameter:
- LLM: Qwen 72B (self-hosted via llama.cpp on local GPU infrastructure) LLM: Qwen 72B (self-hosted via llama.cpp auf lokaler GPU-Infrastruktur)
- LLM timeout: 20 minutes (1,200,000ms) per specialist call — required for Qwen 72B with full production data context LLM-Timeout: 20 Minuten (1.200.000ms) pro Spezialisten-Aufruf — erforderlich für Qwen 72B mit vollem Produktionsdaten-Kontext
- Specialist context: ~7,000 characters input per specialist (production specialist has the most data) Spezialisten-Kontext: ~7.000 Zeichen Input pro Spezialist (Produktionsspezialist hat die meisten Daten)
-
Prompts: Externalized as Markdown files with
{{variable}}templates, loaded vialoadPrompt()from@v7/sharedPrompts: Externalisiert als Markdown-Dateien mit{{variable}}-Templates, geladen vialoadPrompt()aus@v7/shared - Data access: 4 MCP servers (OEE, ERP, Factory, QMS) provide real-time data via standardized tool calls Datenzugriff: 4 MCP-Server (OEE, ERP, Factory, QMS) liefern Echtzeitdaten über standardisierte Tool-Aufrufe
- Progress: SSE (Server-Sent Events) stream each agent's progress to the browser in real-time — you see specialists reporting as they finish Fortschritt: SSE (Server-Sent Events) streamen den Fortschritt jedes Agenten in Echtzeit an den Browser — man sieht Spezialisten berichten, sobald sie fertig sind
Specialist findings are stored in the LangGraph state and passed to the moderator as previousDiscussionContext. This is not just a convenience — it is the mechanism that prevents the moderator from repeating questions and ensures each discussion round builds on the last.
Spezialistenergebnisse werden im LangGraph-State gespeichert und dem Moderator als previousDiscussionContext übergeben. Das ist nicht nur Komfort — es ist der Mechanismus, der verhindert, dass der Moderator Fragen wiederholt, und sicherstellt, dass jede Diskussionsrunde auf der vorherigen aufbaut.
Prompt engineering is the bottleneck, not model size. Getting a specialist to produce consistent, structured analysis requires careful prompt design. The externalized prompt system (config/prompts/agents/*.md) lets you iterate on prompts without touching code. In development mode, prompts reload on every call. In production, they are cached for performance. This separation of prompt logic from application logic is critical at scale.
Prompt Engineering ist der Engpass, nicht die Modellgröße. Damit ein Spezialist konsistente, strukturierte Analysen liefert, braucht es sorgfältiges Prompt-Design. Das externalisierte Prompt-System (config/prompts/agents/*.md) erlaubt Iteration an Prompts ohne Code-Änderungen. Im Development-Modus werden Prompts bei jedem Aufruf neu geladen. In Produktion werden sie gecacht. Diese Trennung von Prompt-Logik und Applikations-Logik ist skalierungskritisch.
Why Not Just Use a Bigger Model? Warum nicht einfach ein größeres Modell?
The obvious objection: “GPT-4 with 128K context could process all this data in one call. Why build this elaborate multi-agent system?” Der offensichtliche Einwand: „GPT-4 mit 128K Kontext könnte all diese Daten in einem Aufruf verarbeiten. Warum dieses aufwendige Multi-Agenten-System bauen?“
Four reasons: Vier Gründe:
1. A bigger model cannot ask follow-up questions to databases. The 47-minute contradiction example above was resolved by fetching NEW data — calibration logs and tool histories that were not in the original prompt. A single-pass model works with whatever data you give it upfront. The debate protocol decides what additional data to fetch based on what it finds. This is a fundamentally different capability. 1. Ein größeres Modell kann keine Rückfragen an Datenbanken stellen. Das 47-Minuten-Widerspruchsbeispiel oben wurde durch Abruf NEUER Daten gelöst — Kalibrierungsprotokolle und Werkzeughistorien, die nicht im ursprünglichen Prompt waren. Ein Ein-Durchlauf-Modell arbeitet mit den Daten, die man ihm vorab gibt. Das Debattenprotokoll entscheidet, welche zusätzlichen Daten basierend auf bisherigen Erkenntnissen geholt werden. Das ist eine fundamental andere Fähigkeit.
2. No internal cross-checking. A single model generates one narrative. If that narrative is wrong, there is no mechanism to catch it. The debate protocol has a built-in correction mechanism: every claim in the draft report gets reviewed by the specialist whose data it cites. Wrong attributions get caught in Round 3. 2. Keine interne Gegenprüfung. Ein einzelnes Modell generiert eine Erzählung. Wenn diese falsch ist, gibt es keinen Mechanismus, sie aufzufangen. Das Debattenprotokoll hat einen eingebauten Korrekturmechanismus: Jede Behauptung im Berichtsentwurf wird vom Spezialisten überprüft, dessen Daten sie zitiert. Falsche Zuordnungen werden in Runde 3 gefunden.
3. Auditability. With the debate protocol, you can trace exactly which domain contributed which finding. The OEE specialist flagged the stoppage. The maintenance specialist confirmed it was scheduled. The quality specialist verified post-calibration Cpk. This audit trail matters in manufacturing — when you implement an action based on AI recommendations, you need to know which data supported it. 3. Nachvollziehbarkeit. Mit dem Debattenprotokoll kann man exakt nachverfolgen, welche Domäne welche Erkenntnis beigesteuert hat. Der OEE-Spezialist markierte den Stillstand. Der Wartungsspezialist bestätigte, dass er geplant war. Der Qualitätsspezialist verifizierte den Cpk nach Kalibrierung. Dieser Audit-Trail ist in der Fertigung wichtig — wenn man eine Maßnahme auf Basis von KI-Empfehlungen umsetzt, muss man wissen, welche Daten sie stützen.
4. Data sovereignty. The debate protocol runs entirely on self-hosted infrastructure. Qwen 72B runs on local GPUs via llama.cpp. Factory data — OEE metrics, quality parameters, maintenance logs, order data — never leaves the premises. Sending all of this to a cloud API is a non-starter for many manufacturers. Learn more about the full technology stack. 4. Datensouveränität. Das Debattenprotokoll läuft vollständig auf selbst gehosteter Infrastruktur. Qwen 72B läuft auf lokalen GPUs via llama.cpp. Fabrikdaten — OEE-Metriken, Qualitätsparameter, Wartungsprotokolle, Auftragsdaten — verlassen nie das Gelände. All dies an eine Cloud-API zu senden, ist für viele Hersteller ein Ausschlusskriterium. Mehr über den vollständigen Technologie-Stack.
Single Large Model Einzelnes großes Modell
- One pass, one narrative, no verificationEin Durchlauf, eine Erzählung, keine Verifikation
- Cannot fetch additional data mid-analysisKann keine zusätzlichen Daten während der Analyse holen
- No audit trail per domainKein Audit-Trail pro Domäne
- Factory data sent to cloud APIFabrikdaten an Cloud-API gesendet
3-Round Debate Protocol 3-Runden-Debattenprotokoll
- Cross-checked by every domain specialistGegengeprüft durch jeden Domänenspezialisten
- Smart deep-dive fetches new data on demandSmart Deep-Dive holt neue Daten bedarfsgesteuert
- Full traceability: which specialist found whatVolle Nachvollziehbarkeit: welcher Spezialist fand was
- Runs on-premises, data never leaves the factoryLäuft on-premises, Daten verlassen nie die Fabrik
The debate protocol gives you better results from a smaller model — because the architecture compensates for what any single model lacks: the ability to question itself, fetch missing data, and have its conclusions challenged before they become recommendations. Das Debattenprotokoll liefert bessere Ergebnisse mit einem kleineren Modell — weil die Architektur kompensiert, was jedem einzelnen Modell fehlt: die Fähigkeit, sich selbst zu hinterfragen, fehlende Daten zu holen und seine Schlussfolgerungen herausfordern zu lassen, bevor sie zu Empfehlungen werden.
This protocol powers the OEE Optimization agent, and the same architecture underlies every optimization agent in the ZeroGuess AI platform. To understand how the data layer connects to these agents, see MCP in Manufacturing. Dieses Protokoll treibt den OEE-Optimierungs-Agenten an, und die gleiche Architektur liegt jedem Optimierungsagenten der ZeroGuess AI Plattform zugrunde. Um zu verstehen, wie die Datenschicht mit diesen Agenten verbunden ist, siehe MCP in der Fertigung.